Since DeepSeek released their latest DeepSeek-v3 and DeepSeek-R1 models, it's like the whole AI field has been injected with new vigor, with more and more new AI models springing up. In addition to the just released Manus, we will also introduce you to the new QwQ-32B model by Ali in this post.
Part 1. All about QwQ-32B Reasoning Model
Qwen is Alibaba's open source Large Language Model (LLM) family. QwQ (Qwen-with-Questions) is an inference model in the Qwen family, which has the ability to think and reason through continuous reinforcement learning (RL) to improve the performance of solving complex tasks, especially in math and coding, as compared to the traditional instruction-tuned models.
The initial version of QwQ, released in November 2024, has 32 billion parameters, 32,000 token lengths and is designed to compete with OpenAI's o1-preview. Although QwQ has made great progress, AI is evolving rapidly and the limitations of traditional LLMs are becoming more apparent. In this context, LRM (Large Reasoning Models) have stirred great interest.

The release of QwQ-32B is undoubtedly in line with the trend of AI development. The development team of QwQ-32B believes that RL can significantly improve the model's ability to solve complex tasks and keep training on this basis. Also inherited in this QwQ-32B reasoning model are the capabilities associated with the Agent, enabling it to think and adjust its reasoning process based on environmental feedback.
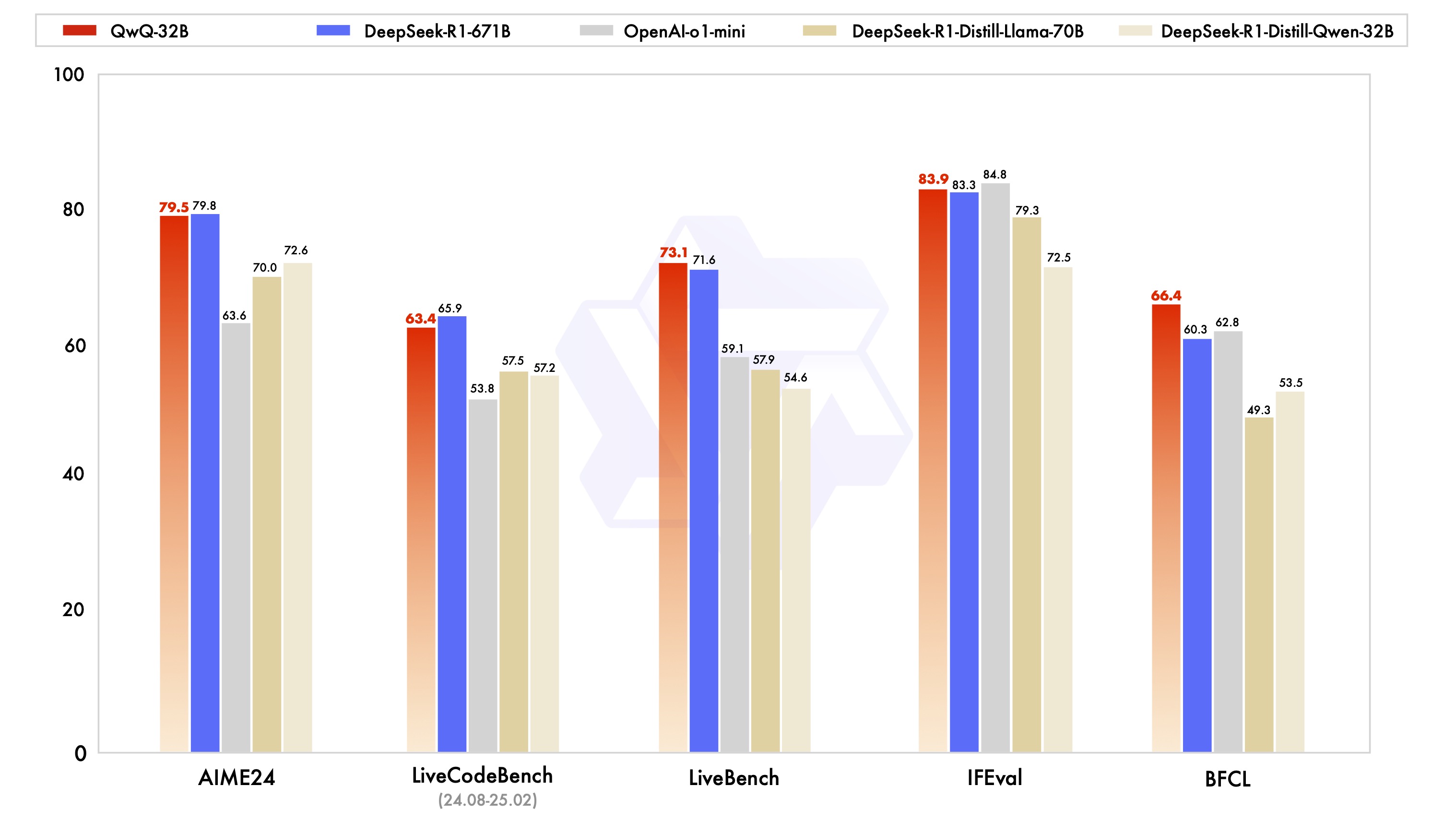
QwQ-32B was evaluated in various benchmark tests for its ability to handle problems such as mathematical reasoning and programming. The figure below illustrates the performance comparison between QwQ-32B and other leading models including DeepSeek-R1, o1-mini and others.
Part 2. Features of the QwQ-32B Model
The QwQ-32B model is not the best inference model, but it is still very competitive. For example, although DeepSeek-R1 has 671 billion parameters, of which 37 billion are activated, QwQ-32B takes up less space while maintaining about the same state of performance realization.
In addition to this, QwQ-32B has been optimized in various ways:
Training phase: pre-training and post-training, mainly focusing on reinforcement learning.
Architecture: RoPE, SwiGLU, RMSNorm and Attention QKV deviation.
Number of layers: 64
Number of GQAs: 40 Attention heads for queries and 8 Attention heads for key-value pairs (40 for Q and 8 for KV).
Context length: 131K+
Part 3. Deploying the QwQ-32B Locally
The model is now available and open source at Hugging Face, ModelScope, etc. You can find the corresponding QwQ-32B API for local deployment just like deploying DeepSeek API.
For a code demo, you can check out Qwen's official documentation:
QwQ-32B: Embracing the Power of Reinforcement Learning.
Part 4. Conclusion
At this stage, AI has been utilized in a wide range of scenarios, the most common of which is still AI intelligent search. The launch of DeepSeek-v3 has made many in the tech field wonder if OpenAI is the final answer. What will artificial intelligence eventually evolve into?
The launch of QwQ-32B not only allows people to witness the potential of reinforcement learning, but also recognizes the possibility of pre-trained language models to be developed.